第 4 章:命名空间 #
4.1: 命名空间 #
想象一下一位数学老师想要开发一个交互式数学程序。对于此程序,诸如 cos 、 sin 、 tan 等函数将用于接受以度为单位的参数,而不是以弧度为单位的参数。不幸的是,函数名称 cos 已被使用,并且该函数接受弧度作为其参数,而不是角度。
此类问题通常通过定义另一个名称来解决,例如定义函数名称 cosDegrees 。 C++ 通过命名空间提供了替代解决方案。命名空间可以被视为代码中可以定义标识符的区域或区域。在命名空间中定义的标识符通常不会与其他地方(即在其命名空间之外)定义的名称冲突。因此,可以在 namespace Degrees 中定义函数 cos (期望角度以度为单位)。当从 Degrees 中调用 cos 时,您将调用需要度数的 cos 函数,而不是需要弧度的标准 cos 函数。
#
4.1.1: 定义命名空间
命名空间根据以下语法定义:
namespace identifier
{
// declared or defined entities
// (declarative region)
}
定义命名空间时使用的 identifier 是标准 C++ 标识符。
在上面的代码示例中引入的声明区域内,可以定义或声明函数、变量、结构、类甚至(嵌套)命名空间。命名空间不能在函数体内定义。但是,可以使用多个命名空间声明来定义命名空间。命名空间是 open ,这意味着命名空间 CppAnnotations 可以在文件 file1.cc 中定义,也可以在文件 file2.cc 中定义。然后,在文件 file1.cc 和 file2.cc 的 CppAnnotations 命名空间中定义的实体将统一在一个 CppAnnotations 命名空间区域中。例如:
// in file1.cc
namespace CppAnnotations
{
double cos(double argInDegrees)
{
...
}
}
// in file2.cc
namespace CppAnnotations
{
double sin(double argInDegrees)
{
...
}
}
sin 和 cos 现在都定义在同一个 CppAnnotations 命名空间中。
命名空间实体可以在其命名空间之外定义。该主题在 [4.1.4.1](/cpp/zh/docs/Name-Spaces/#4141-defining-entities-outside-of-their-namespaces) 节中讨论。
#
4.1.1.1:在命名空间中声明实体
实体也可以在命名空间中声明,而不是在命名空间中定义实体。这允许我们将所有声明放在一个头文件中,然后可以使用命名空间中定义的实体将其包含在源中。这样的头文件可以包含,例如,
namespace CppAnnotations
{
double cos(double degrees);
double sin(double degrees);
}
#
4.1.1.2:封闭的命名空间
命名空间可以在没有名称的情况下定义。这样的匿名名称空间限制了所定义实体对定义匿名名称空间的源文件的可见性。
匿名命名空间中定义的实体相当于 C 的 static 函数和变量。在 C++ 中,仍然可以使用 static 关键字,但它的首选用途是在类定义中(参见第 7 章)。在 C ` static 中使用变量或函数的情况下,应在 C++ 中使用匿名命名空间。
匿名命名空间是一个封闭的命名空间:不可能使用不同的源文件将实体添加到同一匿名命名空间。
#
4.1.2:引用实体
给定命名空间及其实体,范围解析运算符可用于引用其实体。例如,在 CppAnnotations 命名空间中定义的函数 cos() 可以按如下方式使用:
// assume CppAnnotations namespace is declared in the
// following header file:
#include <cppannotations>
int main()
{
cout << "The cosine of 60 degrees is: " <<
CppAnnotations::cos(60) << '\n';
}
这是在 CppAnnotations 命名空间中引用 cos() 函数的一种相当麻烦的方法,尤其是在经常使用该函数的情况下。在此类情况下,可以在指定 using 声明后使用缩写形式。下列的
using CppAnnotations::cos; // note: no function prototype,
// just the name of the entity
// is required.
调用 cos 会导致调用 CppAnnotations 命名空间中定义的 cos 函数。这意味着接受弧度的标准 cos 函数不再自动调用。要调用后一个 cos 函数,应使用普通范围解析运算符:
int main()
{
using CppAnnotations::cos;
...
cout << cos(60) // calls CppAnnotations::cos()
<< ::cos(1.5) // call the standard cos() function
<< '\n';
}
using 声明的范围可以受到限制。它可以在块内使用。 using 声明防止定义与 using 声明中使用的实体同名的实体。不可能在某个命名空间中为变量值指定 using 声明,也无法在也包含 using 声明的块中定义(或声明)同名的对象。例子:
int main()
{
using CppAnnotations::value;
...
cout << value << '\n'; // uses CppAnnotations::value
int value; // error: value already declared.
}
#
4.1.2.1: using 指令
using 声明的通用替代方法是 using 指令:
using namespace CppAnnotations;
遵循此指令,使用 CppAnnotations 命名空间中定义的所有实体就好像它们是通过 using 声明来声明的一样。
虽然 using 指令是导入命名空间的所有名称的快速方法(假设命名空间之前已声明或定义),但它同时也是一种有点肮脏的方法,因为不太清楚实体是什么实际上在特定的代码块中使用。
例如,如果 cos 定义在 CppAnnotations 命名空间中,则在调用 cos 时将使用 CppAnnotations::cos 。但是,如果 CppAnnotations 命名空间中未定义 cos ,则将使用标准 cos 函数。 using 指令不像 using 声明那样清楚地记录实际将使用的实体。因此,应用 using 指令时要小心。
命名空间声明是上下文相关的:当在复合语句内指定 using 命名空间声明时,该声明在遇到复合语句的右花括号之前一直有效。在下一个示例中,定义了字符串 first ,而没有显式指定 std::string ,但是一旦复合语句结束, using namespace std 声明的范围也结束了,并且因此在定义第二个时再次需要 std:: :
#include <string>
int main()
{
{
using namespace std;
string first;
}
std::string second;
}
using 命名空间指令不能在类或枚举类型的声明块中使用。例如,以下示例将无法编译:
struct Namespace
{
using namespace std; // won't compile
};
4.1.2.2: Koenig lookup #
如果柯尼希查找被称为柯尼希原理,它可能是一本新的勒德勒姆小说的标题。然而,事实并非如此。相反,它指的是 C++ 技术细节。
Koenig 查找是指如果调用函数时未指定其名称空间,则使用其参数类型的名称空间来确定该函数的名称空间。如果定义参数类型的命名空间包含这样的函数,则使用该函数。此过程称为 Koenig 查找。
作为说明,请考虑下一个示例。函数 FBB::fun(FBB::Value v) 定义在 FBB 命名空间中。可以在不明确提及其名称空间的情况下调用它:
#include <iostream>
namespace FBB
{
enum Value // defines FBB::Value
{
FIRST
};
void fun(Value x)
{
std::cout << "fun called for " << x << '\n';
}
}
int main()
{
fun(FBB::FIRST); // Koenig lookup: no namespace
// for fun() specified
}
/*
generated output:
fun called for 0
*/
编译器在处理命名空间时相当聪明。如果 namespace FBB 中的值被定义为 using Value = int 那么 FBB::Value 将被识别为 int ,从而导致 Koenig 查找失败。
作为另一个例子,考虑下一个程序。这里涉及两个命名空间,每个命名空间定义自己的 fun 函数。没有歧义,因为参数定义了命名空间并且 FBB::fun 被调用:
#include <iostream>
namespace FBB
{
enum Value // defines FBB::Value
{
FIRST
};
void fun(Value x)
{
std::cout << "FBB::fun() called for " << x << '\n';
}
}
namespace ES
{
void fun(FBB::Value x)
{
std::cout << "ES::fun() called for " << x << '\n';
}
}
int main()
{
fun(FBB::FIRST); // No ambiguity: argument determines
// the namespace
}
/*
generated output:
FBB::fun() called for 0
*/
下面是一个存在歧义的示例: fun 有两个参数,每个名称空间各有一个。程序员必须解决歧义:
#include <iostream>
namespace ES
{
enum Value // defines ES::Value
{
FIRST
};
}
namespace FBB
{
enum Value // defines FBB::Value
{
FIRST
};
void fun(Value x, ES::Value y)
{
std::cout << "FBB::fun() called\n";
}
}
namespace ES
{
void fun(FBB::Value x, Value y)
{
std::cout << "ES::fun() called\n";
}
}
int main()
{
// fun(FBB::FIRST, ES::FIRST); ambiguity: resolved by
// explicitly mentioning
// the namespace
ES::fun(FBB::FIRST, ES::FIRST);
}
/*
generated output:
ES::fun() called
*/
命名空间的一个有趣的微妙之处是,一个命名空间中的定义可能会破坏另一个命名空间中定义的代码。它表明命名空间可能会相互影响,如果我们不了解命名空间的特殊性,命名空间可能会适得其反。考虑以下示例:
namespace FBB
{
struct Value
{};
void fun(int x);
void gun(Value x);
}
namespace ES
{
void fun(int x)
{
fun(x);
}
void gun(FBB::Value x)
{
gun(x);
}
}
无论发生什么,程序员最好不要使用 ES 命名空间中定义的任何函数,因为这会导致无限递归。然而,这不是重点。关键是,由于编译失败,程序员甚至没有机会调用 ES::fun 。
gun 编译失败,但 fun 编译失败。但为什么会这样呢?为什么 ES::fun 可以完美编译,而 ES::gun 却不能?在 ES::fun fun(x) 中被调用。由于 x 的类型未在命名空间中定义,因此 Koenig 查找不适用,并且 fun 通过无限递归调用自身。
对于 ES::gun ,参数是在 FBB 命名空间中定义的。因此, FBB::gun 函数是可能被调用的候选函数。但 ES::gun 本身也是可能的,因为 ES::gun 的原型与调用 gun(x) 完美匹配。
现在考虑 FBB::gun 尚未声明的情况。那么当然就没有任何歧义了。负责 ES 命名空间的程序员正在愉快地休息。一段时间后,维护 FBB 命名空间的程序员决定向 FBB 命名空间添加函数gun(Value x) 可能会更好。现在,命名空间 ES 中的代码突然中断,因为在完全不同的命名空间 ( FBB ) 中进行了添加。命名空间显然并不是完全独立的,我们应该意识到上面这样的微妙之处。稍后在 C++ 注解(第 11 章)中我们将回到这个问题。
Koenig 查找仅在命名空间上下文中使用。如果函数是在命名空间外部定义的,并且定义了在命名空间内部定义的类型的参数,并且该命名空间还定义了具有相同签名的函数,则编译器会在调用该函数时报告歧义。这是一个例子,假设上述命名空间 FBB 也可用:
void gun(FBB::Value x);
int main(int argc, char **argv)
{
gun(FBB::Value{}); // ambiguity: FBB::gun and ::gun can both
// be called.
}
#
4.1.3:标准命名空间
std 命名空间由 C++ 保留。该标准定义了许多作为运行时可用软件一部分的实体(例如 cout 、 cin 、 cerr );标准模板库中定义的模板(参见第 18 章);通用算法(参见第 19 章)在 std 命名空间中定义。
关于上一节中的讨论,在引用 std 命名空间中的实体时可以使用 using 声明。例如,要使用 std::cout 流,代码可以按如下方式声明此对象:
#include <iostream>
using std::cout;
然而,通常情况下,在 std 命名空间中定义的标识符都可以不加考虑地被接受。因此,人们经常会遇到 using directive ,这使得程序员在引用 using directive 指定的命名空间中定义的任何实体时可以省略命名空间前缀。经常遇到以下 using directive ,而不是指定使用声明:类似的构造
#include <iostream>
using namespace std;
是否应该使用 using directive 而不是 using 声明?根据经验,人们可能会决定坚持使用声明,直到列表变得不切实际的长为止,此时可以考虑 using directive 。
使用指令和声明有两个限制:
- 程序员不应在命名空间
std内声明或定义任何内容。这不是编译器强制执行的,而是由标准强加给用户代码的; - 不应将声明和指令的使用强加于第三方编写的代码。实际上,这意味着应禁止在头文件中使用 using 指令和声明,而应仅在源文件中使用(参见第 7.11.1 节)。
#
4.1.4:嵌套命名空间和命名空间别名
命名空间可以嵌套。这是一个例子:
namespace CppAnnotations
{
int value;
namespace Virtual
{
void *pointer;
}
}
变量 value 是在 CppAnnotations 命名空间中定义的。在 CppAnnotations 命名空间内嵌套了另一个命名空间(虚拟)。在后一个命名空间中定义了变量 pointer 。要引用这些变量,可以使用以下选项:
-
可以使用完全限定名称。实体的完全限定名称是在到达实体定义之前遇到的所有命名空间的列表。命名空间和实体通过范围解析运算符粘合在一起:
int main() { CppAnnotations::value = 0; CppAnnotations::Virtual::pointer = 0; } -
可以提供
using namespace CppAnnotations指令。现在值可以不带任何前缀使用,但pointer必须与Virtual::prefix一起使用:using namespace CppAnnotations; int main() { value = 0; Virtual::pointer = 0; } -
可以使用完整命名空间链的 using 命名空间指令。现在 value 再次需要其
CppAnnotations前缀,但pointer不再需要前缀:using namespace CppAnnotations::Virtual; int main() { CppAnnotations::value = 0; pointer = 0; } -
当使用两个单独的 using 命名空间指令时,不再需要任何命名空间前缀:
using namespace CppAnnotations; using namespace Virtual; int main() { value = 0; pointer = 0; } -
通过提供特定的 using 声明,可以对特定变量完成相同的操作(即没有命名空间前缀):
using CppAnnotations::value; using CppAnnotations::Virtual::pointer; int main() { value = 0; pointer = 0; } -
还可以使用 using 命名空间指令和 using 声明的组合。例如,using 命名空间指令可用于
CppAnnotations::Virtual命名空间,而 using 声明可用于CppAnnotations::value变量:using namespace CppAnnotations::Virtual; using CppAnnotations::value; int main() { value = 0; pointer = 0; }
在 using 命名空间指令之后,可以使用该命名空间的所有实体,而无需任何进一步的前缀。如果使用单个 using 命名空间指令来引用嵌套命名空间,则可以使用该嵌套命名空间的所有实体,而无需任何进一步的前缀。但是,在较浅的命名空间中定义的实体仍然需要浅命名空间的名称。只有在提供特定的 using 命名空间指令或 using 声明之后,才能省略命名空间限定。
当首选完全限定名称但使用长名称时,例如
CppAnnotations::Virtual::pointer
被认为太长,可以使用命名空间别名:
namespace CV = CppAnnotations::Virtual;
这将 CV 定义为全名的别名。现在可以使用以下方式访问变量指针:
CV::pointer = 0;
命名空间别名也可以用在 using 命名空间指令或 using 声明中:
namespace CV = CppAnnotations::Virtual;
using namespace CV;
**
嵌套命名空间定义**
从 C++17 标准开始,当嵌套命名空间时,可以使用作用域解析运算符直接引用嵌套命名空间。例如。,
namespace Outer::Middle::Inner
{
// entities defined/declared here are defined/declared in the Inner
// namespace, which is defined in the Middle namespace, which is
// defined in the Outer namespace
}
#
4.1.4.1:在名称空间之外定义实体
并不严格需要在命名空间区域内定义命名空间的成员。但在命名空间之外定义实体之前,必须先在其命名空间内声明该实体。
要在其名称空间之外定义实体,必须通过在成员前面加上名称空间前缀来完全限定其名称。在嵌套命名空间的情况下,可以在全局级别或中间级别提供定义。这允许我们在命名空间 A 区域内定义属于命名空间 A::B 的实体。
假设 int INT8[8] 类型在 CppAnnotations::Virtual 命名空间中定义。此外,假设我们的目的是在命名空间 CppAnnotations::Virtual 内定义一个函数 squares ,返回指向 CppAnnotations::Virtual::INT8 的指针。
在 CppAnnotations::Virtual 命名空间中定义了先决条件后,我们的函数可以定义如下(参见第 9 章内存分配运算符 new[] 的介绍):
namespace CppAnnotations
{
namespace Virtual
{
void *pointer;
using INT8 = int[8];
INT8 *squares()
{
INT8 *ip = new INT8[1];
for (size_t idx = 0; idx != sizeof(INT8) / sizeof(int); ++idx)
(*ip)[idx] = (idx + 1) * (idx + 1);
return ip;
}
}
}
函数 squares 定义了一个由一个 INT8 向量组成的数组,并在用前八个自然数的平方初始化该向量后返回其地址。
现在函数 squares 可以在 CppAnnotations::Virtual 命名空间之外定义:
namespace CppAnnotations
{
namespace Virtual
{
void *pointer;
using INT8 = int[8];
INT8 *squares();
}
}
CppAnnotations::Virtual::INT8 *CppAnnotations::Virtual::squares()
{
INT8 *ip = new INT8[1];
for (size_t idx = 0; idx != sizeof(INT8) / sizeof(int); ++idx)
(*ip)[idx] = (idx + 1) * (idx + 1);
return ip;
}
在上面的代码片段中请注意以下内容:
squares在CppAnnotations::Virtual命名空间内声明。- 命名空间区域之外的定义要求我们使用函数及其返回类型的完全限定名称。
- 在函数方块的主体内部,我们位于
CppAnnotations::Virtual命名空间内,因此在函数内部不再需要完全限定名称(例如,INT8)。
最后,请注意该函数也可以在 CppAnnotations 区域中定义。在这种情况下,在定义 squares() 和指定其返回类型时,将需要 Virtual 命名空间,而函数的内部结构将保持不变:
namespace CppAnnotations
{
namespace Virtual
{
void *pointer;
using INT8 = int[8];
INT8 *squares();
}
Virtual::INT8 *Virtual::squares()
{
INT8 *ip = new INT8[1];
for (size_t idx = 0; idx != sizeof(INT8) / sizeof(int); ++idx)
(*ip)[idx] = (idx + 1) * (idx + 1);
return ip;
}
}
4.2: std::chrono 命名空间(处理时间) #
C 编程语言提供了诸如 sleep(3) 和 select(2) 之类的工具来将程序执行暂停一段时间。当然还有用于设置和显示时间的 time(3) 函数系列
sleep和select可以用于等待,但由于它们是在多线程不可用的时代设计的,因此在多线程程序中使用时它们的用处受到限制。多线程已经成为 C++ 的一部分(在第 20 章中详细介绍),并且 std::filesystem 命名空间中提供了其他与时间相关的函数,本章下面将对此进行介绍。
在多线程程序中,线程经常被挂起,尽管通常挂起的时间很短。例如,当一个线程想要访问一个变量,但该变量当前正在被另一个线程更新时,则前一个线程应该等待,直到后一个线程完成更新。更新变量通常不会花费太多时间,但如果花费了意外的长时间,则前一个线程可能希望了解这一点,以便在后一个线程忙于更新变量时它可以执行其他操作。像这样的线程之间的交互不能用 sleep 和 select 这样的函数来实现。
std::chrono 命名空间弥补了传统可用的时间相关函数与多线程和 std::filesystem 命名空间的时间相关要求之间的差距。包含 <chrono> 头文件后,除了特定的 std::filesystem 相关时间功能之外的所有功能都可用。包含 <filesystem> 头文件后, std::filesystem 的功能就可用了。
时间可以用不同的分辨率来衡量:在奥运会上,数百秒的时间差可能会决定金牌和银牌的区别,但在计划假期时,我们可能会谈论度假前的几个月。时间分辨率是通过类 std::ratio 的对象指定的,该类(除了包含 <chrono> 头文件之外)在包含 <ratio> 头文件后也可用。
不同的事件通常持续不同的时间(给定特定的时间分辨率)。时间量通过 std::chrono::duration 类的对象指定。
事件还可以通过时间点来表征:格林尼治标准时间 1970 年 1 月 1 日午夜是一个时间点,2010 年 12 月 5 日 19:00 也是一个时间点。时间点是通过类 std::chrono::time_point 的对象指定的。 b0> .
不仅事件的分辨率、持续时间和事件的时间点可能不同,而且我们用于指定时间的设备(时钟)也不同。在过去,人们使用沙漏(有时煮鸡蛋时仍然使用它们),但另一方面,当测量需要非常精确时,我们可能会使用原子钟。有四种不同类型的时钟可供选择。常用的时钟是 std::chrono::system_clock ,但在文件系统的上下文中还有一个(隐式定义的) filesystem::__file_clock 。
在接下来的部分中,将介绍 std::chrono 命名空间的详细信息。首先我们看看时间分辨率的特征。接下来介绍如何根据他们的决心来处理时间量。下一节描述用于定义和处理时间点的工具。随后将介绍这些类型和各种时钟类型之间的关系。
在本章中,规范 std::chrono:: 经常被省略(实际上通常使用 using namespace std 后接 using namespace chrono ; [std::]chrono:: 规范偶尔用于避免歧义)。另外,您时不时会遇到对后面章节的前向引用,例如对有关多线程的章节的引用。这些是很难避免的,但幸运的是,此时学习这些章节可以推迟,而不会失去连续性。
#
4.2.1:时间分辨率:std::ratio
时间分辨率(或时间单位)是时间规范的重要组成部分。时间分辨率是通过类 std::ratio 的对象定义的。
在使用类 ratio 之前,必须包含 <ratio> 头文件。相反,可以包含 <chrono> 头文件。
类 ratio 需要两个模板参数。这些是由尖括号括起来的正整数,分别定义分数的分子和分母(默认情况下分母等于 1)。例子:
ratio<1> - representing one;
ratio<60> - representing 60
ratio<1, 1000> - representing 1/1000.
类 ratio 定义了两个可直接访问的静态数据成员: num 代表其分子, den 代表其分母。 ratio 定义本身只是定义了一定的数量。例如,当执行以下程序时
#include <ratio>
#include <iostream>
using namespace std;
int main()
{
cout << ratio<5, 1000>::num << ',' << ratio<5, 1000>::den << '\n' <<
milli::num << ',' << milli::den << '\n';
}
显示文本 1,200,因为这是由 ratio<5, 1000>: ratio 表示的 amount 尽可能简化了分数。
存在相当多的预定义 ratio 类型。它们与 ratio 本身一样,在标准命名空间中定义,可以用来代替更麻烦的 ratio<x> 或 ratio<x, y> 规范:
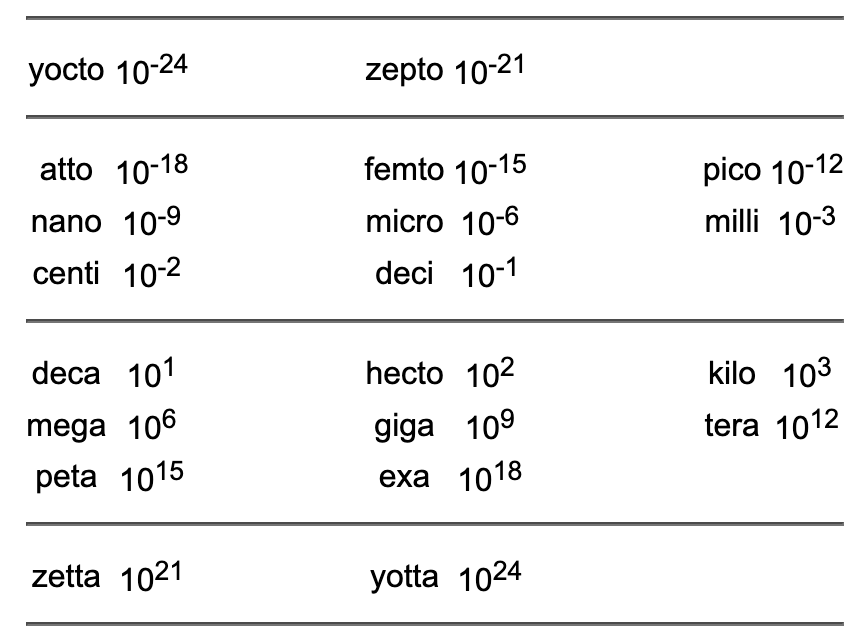
(注意:类型 yocto 、 zepto 、 zetta 和 yotta 的定义使用超过 64 位的整型常量。虽然这些常量是在 C++ 中定义,它们在 64 位或更小的体系结构上不可用。)
与时间相关的比率可以很好地解释为秒的分数或倍数,其中 ratio<1, 1> z 表示一秒的分辨率。
以下示例展示了如何使用这些缩写:
cout << milli::num << ',' << milli::den << '\n' <<
kilo::num << ',' << kilo::den << '\n';
#
4.2.2:时间量:std::chrono::duration
时间量通过 std::chrono::duration 类的对象指定。
在使用类 duration 之前,必须包含 <chrono> 头文件。
就像ratio一样,类 duration 需要两个模板参数。数字类型(通常使用 int64_t )定义保存 duration 时间量的类型,以及时间分辨率(称为其分辨率),通常通过 std::ratio-type (通常使用其计时缩写之一)。
使用预定义的 std::deca 比率,表示以10秒为单位,30分钟的间隔定义如下:
duration<int64_t, std::deca> halfHr(180);
这里 halfHr 代表 180 十秒的时间间隔,即 1800 秒。与预定义比率相比,预定义持续时间类型可用:

使用这些类型,30 分钟的时间量现在可以简单地定义为 minutes halfHour(30) 。
定义持续时间 <Type, Resolution> 时指定的两种类型可以分别检索为:
-
rep,相当于数字类型(如
int64_t)。例如,seconds::rep相当于int64_t; -
period,相当于比率类型(如
kilo),因此duration<int, kilo>::period::num等于 1000。
可以通过指定其数字类型的参数来构造 Duration 对象:
- 持续时间(Type const &value):
value时间单位的特定持续时间。Type指持续时间的数字类型(例如int64_t)。因此,在定义参数 30 时,它存储在其int64_t数据成员中。
Duration 支持 copy- and move-constructors (参见第 9 章),其默认构造函数将其 int64_t 数据成员初始化为零。
存储在持续时间对象中的时间量可以通过添加或减去两个持续时间对象或者通过乘法、除法或计算其数据成员的模值来修改。数字乘法操作数可以用作左侧或右侧操作数;与其他乘法运算符组合时,数字操作数必须用作右侧操作数。复合赋值运算符也可用。一些例子:
minutes fullHour = minutes{ 30 } + halfHour;
fullHour = 2 * halfHour;
halfHour = fullHour / 2;
fullHour = halfHour + halfHour;
halfHour /= 2;
halfHour *= 2;
此外, duration 提供以下成员(第一个成员是需要 duration 对象的普通成员函数)。另外三个是静态成员(参见第 8 章),可以在不需要对象的情况下使用它们(如零代码片段所示):
-
count() const 类型返回存储在
duration对象的数据成员内的值。对于 halfHour,它返回 30,而不是 1800; -
uration<Type,Resolution>::zero():这是一个(不可变的)持续时间对象,其 count 成员返回 0。例如:
seconds::zero().count(); // equals int64_t 0 -
uration::min():一个不可变的持续时间对象,其 count 成员返回其 Type 的最小值(即
std::numeric_limits<Type>::min()(参见第 21.11 节)); -
uration::max():一个不可变的持续时间对象,其 count 成员返回其 Type 的最小值(即
std::numeric_limits<Type>::max())。
Duration 使用不同分辨率的对象可以组合,只要不丢失精度。当使用不同分辨率的 duration 对象组合在一起时,所得分辨率是两者中较精细的一个。当使用复合二元运算符时,接收对象的分辨率必须更精细,否则编译会失败。
minutes halfHour{ 30 };
hours oneHour{ 1 };
cout << (oneHour + halfHour).count(); // displays: 90
halfHour += oneHour; // OK
// oneHour += halfHours; // won't compile
后缀 h 、 min 、 s 、 ms 、 us 、 ns 可以用于整数值,创建相应的 duration 时间间隔。例如, minutes min = 1h 存储 60 in min 。
#
4.2.3:测量时间的时钟
时钟用于测量时间。 C++ 提供了几种预定义的时钟类型,除了其中一种之外,所有这些类型都在 std::chrono 命名空间中定义。时钟 std::filesystem::__file_clock 是个例外(有关详细信息,请参阅 [4.3.1](/cpp/zh/docs/Name-Spaces/#431-the-\_\_file\_clock-type) 节)。
在使用 chrono 时钟之前,必须包含头文件。
在定义时间点时我们需要时钟类型(参见下一节)。所有预定义的时钟类型都定义以下类型:
-
时钟的持续时间类型:Clock::duration(预定义的时钟类型使用纳秒)。例如,
system_clock::duration oneDay{ 24h }; -
时钟的分辨率类型:Clock::period(预定义时钟类型使用 nano)。例如,
cout << system_clock::period::den << '\n'; -
用于存储时间量的时钟类型: Clock::rep (预定义时钟类型使用
int64_t)。例如,system_clock::rep amount = 0; -
用于存储时间点的时钟类型(在下一节中描述):
Clock::time_point(预定义时钟类型使用time_point<system_clock, nanoseconds>)例如,system_clock::time_pointstart。
所有时钟类型都有一个成员 now ,返回与当前时间(相对于时钟纪元)相对应的时钟类型的 time_point 。它是一个静态成员,可以这样使用: system_clock::time_point tp = system_clock::now() 。
chrono 命名空间中有三种预定义的时钟类型:
- system_clock 是
wall clock,使用系统的实时时钟; - stable_clock是一个时钟,其时间随着实时时间的增加而平行增加;
- high_resolution_clock 是计算机最快的时钟(即具有最短定时器滴答间隔的时钟)。实际上,这与
system_clock相同。
这些时钟类型还另外在 std::filesystem 命名空间中定义了 __file_clock 时钟类型。 __file_clock 的纪元时间点与其他时钟类型使用的纪元时间不同,但 __file_clock 有一个静态成员 to_sys(__file_clock::time_point) 转换 __file_clock::time_points 到 system_clock::time_points ( __file_clock 在 [4.3.1]((/cpp/zh/docs/Name-Spaces/#431-the-\_\_file\_clock-type)))。
除了 now 之外,类 system_clock 和 high_resolution_clock (下面称为 Clock)还提供这两个静态成员:
std::time\_t 时钟::to\_time\_t(时钟::time\_point const &tp)**
一个 `std::time_t` 值(与 C 的 `time(2)` 函数返回的类型相同),表示与 `timePoint` 相同的时间点。
时钟::time\_point 时钟::from\_time\_t(std::time\_t 秒)**
a `time_point` 代表与 `time_t` 相同的时间点。
该示例说明了如何调用这些函数:
system_clock::from_time_t(
system_clock::to_time_t(
system_clock::from_time_t(
time(0);
)
)
);
#
4.2.4: 时间点:std::chrono::time_point
可以通过类 std::chrono::time_point 的对象来指定单个时刻。
在使用类 time_point 之前,必须包含 <chrono> 头文件。
与 duration 一样,类 time_point 需要两个模板参数: clock 类型和 duration 类型。通常 system_clock 用作时钟类型,使用 nanoseconds 作为默认持续时间类型(如果 nanoseconds 是预期持续时间类型,则可以省略)。否则,将持续时间类型指定为 time_point 的第二个模板参数。因此,以下两个时间点定义使用相同的时间点类型:
time_point<standard_clock, nanoseconds> tp1;
time_point<standard_clock> tp2;
类 time_point 支持三个构造函数:
-
time_point():
默认构造函数被初始化为时钟纪元的开始。对于
system_clock来说,它是 1970 年 1 月 1 日 00:00h,但请注意filesystem::__file_clock使用了不同的纪元(请参阅下面的第 4.3.1 节); -
time_point(time_point<时钟, 持续时间> const &other):
copy constructor(参见第 9 章)使用other定义的时间点初始化time_point对象。如果other的分辨率使用的周期大于构造对象的周期,则other的时间点将在构造对象的分辨率中表示(下面提供了说明,位于成员time_since_epoch的描述); -
time_point(time_point const &&tmp):
move constructor(参见第 9 章)的作用与copy constructor类似,将 tmp 的分辨率转换为构造对象,同时将 tmp 移动到构造的对象。
可以使用以下操作员和成员:
-
time_point &operator+=(duration const &amount):将
amount表示的时间的amount添加到当前time_point对象中。此运算符也可用作使用time_point const &和duration const & operand(以任何顺序)的二元算术运算符。例子:system_clock::now() + seconds{ 5 }; -
time_point &operator-=(duration const &amount):从当前
time_point对象中减去amount表示的时间量。该运算符也可用作使用 time_point const & 和持续时间 const & 操作数(以任何顺序)的二元算术运算符。例子:time_point<system_clock> point = system_clock::now(); point -= seconds{ 5 }; -
uration time_since_epoch() const:
duration是调用该成员的时间点对象所使用的duration类型。它返回自对象表示的纪元以来的时间量。 -
time_point min() const:返回时间点的
duration::min值的静态成员。例子:cout << time_point<system_clock>::min().time_since_epoch().count() << '\n'; // shows -9223372036854775808 -
time_point max() const:返回时间点的
duration::max值的静态成员。
所有预定义的时钟都使用纳秒作为其时间分辨率。要以不太精确的分辨率表示时间,请采用不太精确的分辨率的一个时间单位(例如 hours(1) )并将其转换为纳秒。然后将时间点的 time_since_epoch().count() 成员返回的值除以转换为纳秒的不太精确分辨率的 count 成员。使用此过程可以确定自纪元开始以来经过的小时数:
cout << system_clock::now().time_since_epoch().count() /
nanoseconds(hours(1)).count() <<
" hours since the epoch\n";
基于系统时钟或高分辨率时钟的时间点对象可以转换为 std::time_t (或等效类型 time_t )值。将时间转换为文本时会使用此类 time_t 值。对于此类转换,通常使用操纵器 put_time (参见第 6.3.2 节),但必须为 put_time 提供 std::tm 对象的地址,该对象依次可以从 std::time_t 值获得。整个过程相当复杂,核心要素如图3所示。
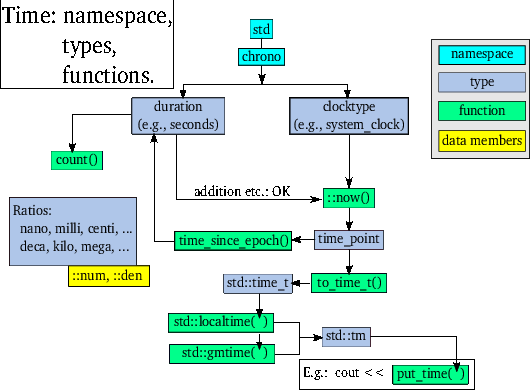
最终导致将时间点的值插入 std::ostream 的基本步骤包括使用 system_clock::to_time_t(time_point<system_clock> const &tp) 将时间点转换为 time_t 值(而不是使用 system_clock 也可以使用 high_resolution_clock )。第 6.4.4 节描述了如何将时间点插入到 std::ostream 中。
4.3: std::filesystem 命名空间 #
计算机通常将重新启动后必须保存的信息存储在其文件系统中。传统上,为了操作文件系统,C 编程语言提供执行所需系统调用的函数。此类函数(如 rename(2) 、 truncate(2) 、 opendir(2) 和 realpath(3) )当然也可以在 C++ 中使用,但是它们的签名和方式使用通常不太有吸引力,因为它们通常期望 char const * 参数,并且可能使用基于 malloc(3) 和 free(3) 的静态缓冲区或内存分配。
自 2003 年以来,Boost 库提供了这些函数的包装器,为那些更像 C++ 的系统调用提供了接口。
目前C++直接支持 std::filesystem 命名空间中的这些函数。这些功能可以在包含 <filesystem> 头文件后使用。
filesystem 命名空间非常广泛:它包含 10 多个不同的类和 30 多个自由函数。要引用 std::filesystem 命名空间中定义的标识符,可以使用它们的完全限定名称(例如 std::filesystem::path )。或者,在指定 using namespace std::filesystem; 后,可以使用标识符而无需进一步限定。还会遇到像 namespace fs = std::filesystem; 这样的命名空间规范,允许像 fs::path 这样的规范。
filesystem 命名空间中的函数可能会失败。当函数无法执行分配给它们的任务时,它们可能会抛出异常(参见[第 10 章]),或者它们可能会将值分配给作为参数传递给这些函数的 error_code 对象(请参阅第 [4.3.2]( /cpp/zh/docs/Name-Spaces/#432-the-class-error\_code) 下面)。
4.3.1: the __file_clock type #
[4.3.2](/cpp/zh/docs/Name-Spaces/#432-the-class-error\_code) 节中指出,可以使用各种预定义时钟,其中 system_clock 指计算机本身使用的时钟。文件系统命名空间使用不同的时钟: std::filesystem::__file_clock 。使用 __file_clock 获取的时间点与使用系统时钟获取的时间点不同:使用 __file_clock 获取的时间点基于(当前)远远超出 1 月 1 日纪元的纪元,系统时钟使用的 1970 年 00:00:00:Fri Dec 31 23:59:59 2173。这两个纪元可以定位在时间尺度上,当前时间介于两者之间:
<------|-----------------------|-----------------------|------->
system_clock's --------> present <-------- __file_clock's
epoch starts positive negative epoch starts
count count
__file_clock 有其自身的特点:静态成员 now 可用,一些非静态成员也可用: durations 和成员 time_since_epoch 都可以使用,并且 .其他成员( to_time_t 、 from_time_t 、 min 和 max )不可用。
由于 to_time_t 不可用于 __file_clock ,我们如何显示时间或获取 time_point<__file_clock> 对象的时间组成部分?
目前,有两种方法可以实现此目的:计算校正 by hand 或使用静态 __file_clock::to_sys 函数将 __file_clock 时间点转换为 time_point 、 steady_clock 和 high_resolution_clock 使用。
计算纪元之间的差异,我们发现 6'437'663'999 秒,我们可以将其添加到自 __file_clock 纪元以来获得的时间,以获得自 system_clock 以来的时间的纪元。如果 timePt 保存自 __file_clock 纪元以来的持续时间,则
6'437'663'999 + system_clock::to_time_t(
time_point<system_clock>{ nanoseconds(timePt) })
等于自 system_clock 纪元以来的秒数。
此过程的潜在缺点是,由于 __file_clock 的名称以下划线开头,因此其纪元的开始可能会改变。通过使用两个时钟的 now 成员可以避免这个缺点:
auto systemNow = system_clock::now().time_since_epoch();
auto fileNow = __file_clock::now().time_since_epoch();
time_t diff = (systemNow - fileNow) / 1'000'000'000;
time_t seconds = diff + system_clock::to_time_t(
time_point<system_clock>{ nanoseconds(timePt) });
尽管从理解的角度来看,能够自己计算时移很有吸引力,但对于日常实践来说可能也有点(太)麻烦了。静态函数 __file_clock::to_sys 可用于将 __file_clock::time_points 转换为 system_clock:::time_points 。 __file_clock::to_sys 函数在 [4.3.3.2](/cpp/zh/docs/Name-Spaces/#4332-free-functions) 节中介绍。
#
4.3.2:error_code 类
std::error_code 类的对象封装错误值和关联的错误类别(参见第 10.9 节; error_code 可以在包含 <system_error> 标头后使用,但它是包含 <filesystem> 头文件后也可用)。传统上,错误值可用作分配给全局 int errno 变量的值。按照惯例,当 errno 的值等于零时,不会出现错误。 error_code 采用了该约定。
可以为许多概念上不同的情况定义错误代码。这些情况都有自己的错误类别。
错误类别用于将 error_code 对象与这些类别定义的错误相关联。默认可用的错误类别可以使用诸如 EADDRINUSE (或等效的 enum class errc 值 address_in_use )之类的值,但也可以根据其他上下文定制新类型的错误类别。定义的。 C++ 注释(第 23.7.1 节)末尾附近介绍了定义错误类别。至此两个 error_category 成员简单介绍一下:
- std::string message(int err) 返回错误 err 的文本描述(例如当
err等于address_in_use时已使用的地址)。 - char const *name() 返回错误类别的名称(如通用类别的 generic );
错误类别类是单例类:每个错误类别仅存在一个对象。在文件系统命名空间的上下文中,使用标准类别 system_category ,并且自由函数 std::system_category 返回对 system_category 对象的引用,不需要任何参数。类 error_code 的公共接口声明了这些构造函数和成员:
建设者:
-
error_code() noexcept:该对象使用错误值 0 和
system_category错误类别进行初始化。值 0 不被视为错误; -
可以使用复制和移动构造函数;
-
error_code(int ec, error_category const &cat) noexcept:对象从错误值
ec初始化(例如,errno,由失败的函数设置),以及对适用的 const 引用错误类别(由std::system_category()或std::generic_category()等提供)。下面是定义error_code对象的示例:error_code ec{ 5, system_category() }; -
error_code(ErrorCodeEnum value) noexcept:这是一个成员模板(参见第 22.1.3 节),使用
template header template <class ErrorCodeEnum>。它使用返回值make_error_code(value)初始化对象(见下文)。第 23.7 节介绍了ErrorCodeEnums的定义。注意:ErrorCodeEnum本身不存在。它只是现有ErrorCodeEnum枚举的占位符;
Members:
可以使用重载赋值运算符和接受 ErrorCodeEnum 的赋值运算符;
-
void allocate(int val, error_category const &cat):为对象的错误值和类别分配新值。例如,ec。
assign(0, generic_category()); -
error_category const &category() const noexcept:返回对象错误类别的引用;
-
void clear() noexcept:将
error_code的值设置为 0 并将其错误类别设置为system_category; -
error_condition default_error_condition() const noexcept:返回用当前对象的错误值和错误类别初始化的当前类别的默认错误条件(有关类
error_condition的详细信息,请参阅第 10.9.2 节); -
string message() const:返回与当前对象的错误值关联的消息(相当于
category().message(ec.value())); -
显式运算符 bool() const noexcept:如果对象的错误值不等于 0,则返回 true(即,它表示 和
error) -
int value() const noexcept:返回对象的错误值。
Free functions:
两个 error_code 对象可以比较(in)相等性并且可以排序(使用 operator< )。
与不同错误类别关联的排序 error_codes 没有意义。但是,当错误类别相同时,则通过错误代码值进行比较(参见本 SG14 讨论摘要);
-
error_code make_error_code(errc value) noexcept:返回一个用
static_cast<int>(value)和generic_category()初始化的error_code对象。此函数将枚举class errc值转换为error_code。还可以定义与定制的
make_error_code函数相关联的其他错误相关枚举(参见第 23.7 节;) -
std::ostream &operator«(std::ostream & os, error_code const &ec): 执行以下语句:
return os << ec.category().name() << ':' << ec.value();
下面介绍的几个函数定义了一个可选的最后一个 error_code &ec 参数。这些函数没有任何规范。如果这些函数无法完成其任务,则将 ec 设置为适当的错误代码,如果没有遇到错误,则调用 ec.clear() 。如果未提供 ec 参数,则这些函数无法完成任务时将引发 filesystem_error 异常。
#
4.3.3:文件系统条目名称:路径
filesysten::path 类的对象保存文件系统条目的名称。类 path 是一个值类:可以使用默认构造函数(空路径)以及标准复制/移动构造/赋值功能。此外,还可以使用以下构造函数:
- path(string &&tmp);
- path(Type const &source):提供路径字符的任何可接受的类型(例如,
source是NTBS); - path(InputIter begin, InputIter end):从
begin到end的字符定义路径的名称。
这样构造的 path 不必引用现有的文件系统条目。
Path 构造函数期望字符序列(包括 NTBSs )可能由各种(所有可选)元素组成:
- 根名称,例如磁盘名称(如 E:)或设备指示符(如 //nfs);
- 根目录,如果它是(可选)根名称之后的第一个字符,则存在;
- 文件名字符(不包含目录分隔符)。另外
single dot filename (.)代表当前目录,double dot filename (..)代表当前目录的父目录; - 目录分隔符(默认为正斜杠)。多个连续的分隔符会自动合并为一个分隔符。
构造函数还定义了最后一个 format ftmp = auto_format 参数,实际上几乎不需要提供参数(有关其详细信息,请参阅 cppreference。)
许多函数需要路径参数,这些参数通常可以从 NTBSs 或 std::string 对象创建,因为路径允许升级(参见第 11.5 节)。例如,文件系统函数 absolute 需要一个 const &path 参数。可以这样调用: absolute("tmp/filename") 。
#
4.3.3.1:访问器、修饰符和运算符
类 path 提供以下运算符和成员:
Operators:
-
path &operator/=(Type const &arg):可以传递给构造函数的参数也可以传递给该成员。
arg参数通过目录分隔符与路径的当前内容分隔开(除非路径最初为空,如 cout « path{}.append(“entry”) 中所示)。另请参见下面的成员append和concat。自由运算符/接受两个path(可提升)参数,返回一个path,其中包含由目录分隔符分隔的两个路径(例如lhs / rhs返回包含lhs/rhs的路径对象); -
path &operator+=(Type const &arg):与
/=类似,但将arg添加到当前path时不使用目录分隔符; -
比较运算符:可以使用(隐含的运算符)
==和<=>运算符来比较path对象。路径对象通过字典顺序比较其ascii-character内容进行比较。
Accessors:
访问器返回特定的 path 组件。如果路径不包含所请求的组件,则返回空的 path 。
-
**char const *c_str()**:返回
NTBS形式的路径内容; -
path extension() 返回路径最后一个组件的点扩展名(包括点);
-
path filename() 返回当前
path对象的最后一个路径内容。另请参阅下面的stem()访问器; -
bool is_absolute():如果
path对象包含绝对路径规范,则返回true; -
bool is_relative():如果
path对象包含相对路径规范,则返回true; -
pathparent_path() 返回当前路径内容,其中最后一个元素已被删除。请注意,如果
path对象包含文件名的路径(如"/usr/bin/zip"),则parent_path删除/zip并返回/usr/bin,所以不是zip的父目录,而是它的实际目录; -
pathrelative_path():返回
path对象的路径根目录组件之外的路径内容。例如,如果定义了路径ulb{ "/usr/local/bin" },则ulb.relative_path()返回包含"usr/local/bin"的路径; -
path root_directory():返回
path对象的根目录部分; -
path root_name():返回
path对象的 root-name 组成部分; -
path root_path():返回
path对象的根路径组件; -
path Stem() 返回当前
path对象的最后一个路径内容,其中dot-extension哈希值已被删除; -
string():以
std::string形式返回路径的内容。类似的访问器可用于以下字符串类型:
wstring、u8string、u16string、u32string、generic_string、generic_wstring、generic_u8string、generic_u16string和generic_u32string;
除了 string() 系列和 is_... 访问器之外,如果路径包含指定组件(例如 has_extension
会员职能:
-
path &append(Type const &arg) 的作用类似于
/=运算符; -
path::iterator begin() 返回一个包含第一个路径组件的迭代器;取消引用
path::iterator返回一个路径对象。当可用的根名称和根目录作为初始组件返回时。当递增
path::iterators时,将返回各个目录和最后的文件名组件。取消引用后续path::iterators时,不会返回目录分隔符本身; -
voidclear():路径的内容被删除;
-
int 比较(类型 const &other):
返回当前
path的内容与other按字典顺序比较的结果。Other可以是path、string-type或NTBS; -
path &concat(Type const &arg) 的作用类似于
+=运算符; -
ostream &operator«(ostream &out, path const &path) (流插入)将
path的内容(用双引号引起来)插入到out中; -
istream &operator»(istream &in, path &path) 从 in 中提取路径的内容。提取的路径名可以选择用双引号引起来。插入先前提取的路径对象时,仅显示一组周围的引号。
-
path &remove_filename():删除存储路径的最后一个组成部分。如果仅存储根目录,则删除根目录。请注意,保留最后一个目录分隔符,除非它是唯一的路径元素;
-
路径 &replace_extension(path const &replacement = path{} ):
将存储路径的最后一个组件的扩展名(包括扩展名的点)替换为
replacement。如果replacement为空,则扩展名将被删除。如果调用replace_extension的path没有扩展名,则添加replacement。replacement可以选择以点开头。path对象的扩展仅接收一个点; -
路径 &replace_filename(路径 const &replacement):
将存储路径的最后一个组件替换为
replacement,它本身可能包含多个路径元素。如果仅存储根目录,则将其替换为replacement。如果当前路径对象为空,则成员的行为未定义;
4.3.3.2: Free functions #
除了 path 成员函数之外,还可以使用各种免费函数。其中一些复制文件。这些函数接受可选的 std::filesystem::copy_options 参数。枚举类 copy_options 定义可用于微调这些函数的行为的符号常量。枚举支持按位运算符(符号的值显示在括号之间)并定义这些符号:
- When copying files:
*
无 (0):报告错误(默认行为); *
Skip_existing(1):保留现有文件,不报错; *
overwrite_existing(2):替换现有文件; *
update_existing (4):仅当现有文件比正在复制的文件旧时才替换它; *
复制子目录时: *
无 (0):跳过子目录(默认行为); *
recursive(8):递归复制子目录及其内容;- 复制符号链接时:
*
无 (0):遵循符号链接(默认行为); *
copy_symlinks (16):将符号链接复制为符号链接,而不是复制为它们指向的文件;- skip_symlinks (32): ignore symlinks;
- 要控制副本本身的行为:
- none (0): copy file content (default behavior);
- directories_only (64):复制目录结构,但不复制任何非目录文件;
- create_symlinks (128):不创建文件副本,而是创建指向原始文件的符号链接(源路径必须是绝对路径,除非目标路径位于当前目录中);
- create_hard_links (256):创建解析为与原始文件相同的文件的硬链接,而不是创建文件的副本。
- 复制符号链接时:
*
以下函数需要路径参数:
-
path Absolute(path const &src, [, error_code &ec]): 指定为绝对路径的
src副本(即从文件系统的根(也可能是磁盘)名称开始)。可以这样调用:absolute("tmp/filename"),返回(绝对)当前工作目录,absolute的参数作为最终元素附加到该目录,并由目录分隔符分隔。保留相对路径指示符(如../和./)。返回的路径仅仅是绝对路径。如果要删除相对的path指示符,则使用下一个函数; -
path canonical(path const &src [, error_code &ec]): 返回
src的规范路径。参数src必须引用现有的目录条目。例子:path man{ "/usr/local/bin/../../share/man" }; cout << canonical(man) << '\n'; // shows: "/usr/share/man" -
void copy(path const &src, path const &dest [, copy_options opts [, error_code &ec]]):
src必须存在。如果cp程序也成功,则将src复制到dest。如果
src是目录,并且dest不存在,则创建dest。如果复制选项递归或未指定,则递归复制目录; -
bool copy_file(path const &src, path const &dest [, copy_options opts [, error_code &ec]]):
src必须存在。如果cp程序也成功,则将src复制到dest。遵循符号链接。复制成功则返回true; -
void copy_symlink(path const &src, path const &dest [, error_code &ec]):创建符号链接
dest作为符号链接src的副本; -
bool create_directories(path const &dest [, error_code &ec]):创建
dest的每个组件,除非已经存在。如果实际创建了dest,则返回 true 值。如果返回 false,则ec包含error-code,如果dest已存在,则该值为零 (ec.value() == 0)。另请参见下面的create_directory; -
bool create_directory(path const &dest [, path const &existing] [, error_code &ec]):
dest的父目录必须存在。如果目录dest尚不存在,则此函数将创建该目录。如果实际创建了dest,则返回 true 值。如果返回 false,则 ec 包含一个错误代码,如果dest已存在,则该错误代码为零 (ec.value() == 0)。如果指定了existing,则dest接收与existing相同的属性; -
void create_directory_symlink(path const &dir, path const &link [, error_code &ec]):类似于
create_symlink(见下文),但用于创建到目录的符号链接; -
void create_hardlink(path const &dest, path const &link [, error_code &ec]):创建从
link到dest的硬链接。dest必须存在; -
void create_symlink(path const &dest, path const &link [, error_code &ec]):创建从
link到dest的符号(软)链接;dest不一定存在; -
path current_path([error_code &ec]), void current_path(path const &toPath [, error_code &ec]):前一个函数返回当前工作目录(
cwd),后者更改cwd到toPath。返回的path的最后一个字符不是斜杠,除非从根目录调用; -
bool equal(path const &path1, path const &path2 [, error_code &ec]):如果
path1和path2引用相同的文件或目录,并且具有相同的状态,则返回 true。两条路径都必须存在; -
bool contains(path const &dest [, error_code &ec])、exists(file_status status):如果
dest存在则返回 true(实际上:如果status(dest[, ec])(见下文)返回 true)。注意:当迭代目录时,迭代器通常提供条目的状态。在这些情况下,调用exists(iterator->status())比调用exists(*iterator)更有效。当dest是符号引用的路径时,exists 返回链接的目标是否存在(另请参见[4.3.4.3.1]节中的函数status和symlink_status。 4](/cpp/zh/docs/Name-Spaces/#434-handling-directories-directory\_entry)); -
std::unintmax_t file_size(path const &dest [, error_code &ec]):返回常规文件(或符号链接目标)的大小(以字节为单位);
-
std::uintmax_t hard_link_count(path const &dest [, error_code &ec]): 返回与
dest关联的硬链接数量; -
time_point<__file_clock> last_write_time(path const &dest [, error_code &ec]), void last_write_time(path const &dest, time_point<__file_clock> newTime [, error_code &ec]): 前一个函数返回
dest的最后修改时间;后一个函数将dest的最后修改时间更改为 newTime。last_write_time的返回类型是通过chrono::time_point的 using 别名定义的(参见第 4.2.4 节)。返回的time_point保证覆盖当前文件系统中可能遇到的所有文件时间值。函数__file_clock::to_sys(见下文)可用于将__file_clock时间点转换为system_clock time_points; -
path read_symlink(path const &src [, error_code &ec]):
src必须引用符号链接,否则会生成错误。返回链接的目标; -
bool remove(path const &dest [, error_code &ec]), std::uintmax_t remove_all(path const &dest [, error_code &ec]):
remove删除文件、符号链接或空目录dest,则返回 true;如果remove_all是文件(或符号链接),则删除dest;并递归删除目录dest,返回删除的条目数; -
void rename(path const &src, path const &dest [, error_code &ec]):将
src重命名为dest,就像使用标准mv(1)命令一样(如果 < b3>存在则被覆盖); -
void resize_file(path const &src, std::uintmax_t size [, error_code &ec]):
src的大小更改为size,就像使用标准truncate(1)命令; -
space_info space(path const &src [, error_code &ec]):返回
src所在文件系统的信息; -
path system_complete(path const &src[, error_code& ec]):返回匹配
src的绝对路径,以current_path作为基础; -
path temp_directory_path([error_code& ec]):返回可用于临时文件的目录的路径。该目录并未创建,但其名称通常可从环境变量
TMPDIR、TMP、TEMP或TEMPDIR中获取。否则,返回/tmp。 -
time_point __file_clock::to_sys(time_point<__file_clock> timePoint):以下是如何使用
system_clock的纪元来表示last_write_time返回的时间:int main() { time_t seconds = system_clock::to_time_t( __file_clock::to_sys(last_write_time("lastwritetime.cc")) ); cout << "lastwritetime.cc's last (UTC) write time: " << put_time(gmtime(&seconds), "%c") << '\n'; }
#
4.3.4:处理目录:directory_entry
文件系统是一种递归数据结构。它的顶级条目是一个目录(根目录),包含普通目录条目(文件、(软)链接、命名套接字等),也可能包含引用嵌套目录的(子)目录条目,而嵌套目录又可能包含普通目录和(子)目录条目。
在 std::filesystem 命名空间中,目录的元素是类 directory_entry 的对象,包含该目录条目的名称和状态。
类 directory_entry 支持所有标准构造函数和赋值运算符,此外还有一个需要 path 的构造函数:
directory_entry(path const &entry);
类 directory_entry 的对象可以通过名称来构造,而不要求这些对象引用计算机文件系统中的现有条目。赋值运算符也可用,就像 ( ostream ) 插入运算符一样,将对象的 path 插入到流中。提取运算符不可用。
directory_entry 对象可以使用 == 、 != 、 < 、 <= 、 > 运算符。然后将这些运算符应用于它们的路径对象: directory_entry("one") == directory_entry("one") 返回 true。
除了这些运算符之外,类 directory_entry 还具有以下成员函数:
-
void allocate(path const &dest):将当前路径替换为
dest(其作用与重载赋值运算符相同); -
void Replace_filename(path const &dest):当前对象路径的最后一个元素被 dest 替换。如果该元素为空(例如对象的路径以目录分隔符结尾),则 dest 将附加到当前对象的路径;
-
path const &path() const, 运算符path const &() const:返回当前对象的路径名;
-
filesystem::file_status status([error_code &ec]):返回当前对象引用的目录条目的类型和属性。如果当前对象引用符号链接,则返回符号链接引用的条目的状态。要获取条目本身的状态,即使它是符号链接,也可以使用
symlink_status(另请参阅第 [4.3.5](/cpp/zh/docs/Name-Spaces/#435-types-file\_type- and-permissions-perms-of-file-system-elements-file\_status) 和 [4.3.5.1](/cpp/zh/docs/Name-Spaces/#4351-获取文件状态-system-entries) 下面)。
#
4.3.4.1:访问目录条目:(recursive_)directory_iterator
filesystem 命名空间有两个类来简化目录处理:类 directory_iterator 的对象是在目录条目上迭代的(输入)迭代器;类 recursive_directory_iterator 的对象是递归访问目录所有条目的(输入)迭代器。
类 (recursive_)directory_iterator 提供默认构造函数、复制构造函数和移动构造函数。这两个类的对象也可以由 path 和可选的 error_code 构造。例如。,
directory_iterator(path const &dest [, error_code &ec]);
支持标准输入迭代器的所有成员(参见第 18.2 节)。这些迭代器指向 directory_entry 对象,这些对象引用计算机文件系统中的条目。例如。,
cout << *directory_iterator{ "/home" } << '\n'; // shows the first
// entry under /home
匹配这些对象的结束迭代器可以通过两个类的默认构造对象获得。此外,还可以使用基于范围的 for 循环,如下例所示:
for (auto &entry: directory_iterator("/var/log"))
cout << entry << '\n';
也可以使用显式定义迭代器的 For 语句:
for (
auto iter = directory_iterator("/var/log"),
end = directory_iterator{};
iter != end;
++iter
)
cout << entry << '\n';
构造 (recursive_)directory_iterator base{"/var/log"} 对象后,它引用其目录的第一个元素。此类迭代器也可以显式定义: auto &iter = begin(base) 、 auto iter = begin(base) 、 auto &iter = base 或 auto iter = base 。所有这些 iter 对象都引用 base 的数据,并且递增它们也会使 base 前进到其下一个元素:
recursive_directory_iterator base{ "/var/log/" };
auto iter = base;
// final two elements show identical paths,
// different from the first element.
cout << *iter << ' ' << *++iter << ' ' << *base << '\n';
上面示例中使用的函数 begin 和 end 与 (recursive_)directory_iterator 一样,可在 filesystem 命名空间中使用。
recursive_directory_iterator 还接受 directory_options 参数(见下文),默认指定为 directory_options::none :
recursive_directory_iterator(path const &dest,
directory_options options [, error_code &ec]);
枚举类 directory_options 定义用于微调 recursive_directory_iterator 对象行为的值,支持按位运算符(其符号值显示在括号之间):
- none (0):跳过目录符号链接,拒绝进入子目录的权限会生成错误;
- follow_directory_symlink (1):跟随到子目录的符号链接;
- Skip_permission_denied (2):静默跳过无法进入的目录。
类 recursive_directory_iterator 也有以下成员:
-
int depth() const:
返回当前迭代深度。初始目录的深度,在构造时指定,等于 0;
-
无效disable_recursion_pending():
当在递增迭代器之前调用时,如果下一个目录条目是子目录,则不会递归访问它。然后,在增加迭代器之后,再次允许递归。如果递归应在特定深度结束,则一旦
depth()返回该特定深度,则必须在调用迭代器的增量运算符之前重复调用此函数; -
递归目录迭代器&增量(错误代码&ec):
其作用与迭代器的增量运算符相同。但是,当发生错误时
operator++会抛出filesystem_error异常,而increment将错误分配给ec; -
目录选项 options() const:
返回构造时指定的
option(s); -
void pop():
结束处理当前目录,并继续处理当前目录父目录中的下一个条目。当(在 for 语句中,参见下面的示例)从初始目录调用时,目录的处理结束;
-
bool recursion_pending() const:
如果允许递归处理当前处理目录的子目录,则返回 true。如果是这样,并且迭代器指向的目录条目是子目录,则在迭代器的下一个增量处继续在该子目录处进行处理;
这是一个小程序,显示目录及其所有直接子目录的所有目录元素。
int main()
{
recursive_directory_iterator base{ "/var/log" };
for (auto entry = base, endIt = end(base); entry != endIt; ++entry)
{
cout << entry.depth() << ": " << *entry << '\n';
if (entry.depth() == 1)
entry.disable_recursion_pending();
}
}
上面的程序处理条目。如果需要其他策略,则必须实施它们。例如,广度优先策略首先访问所有非目录条目,然后访问子目录。在下一个示例中,这是通过处理 level 中存储的每个目录来实现的(最初它仅包含起始目录)。处理目录意味着直接处理其非目录条目,而其子目录的名称存储在 next 中。一旦 level 中的所有条目都已处理完毕,下一级子目录的名称就可以在 next 中使用,并且通过将 next 分配给级别,可以处理下一级的所有目录。当到达最深嵌套的子目录时 next 保持为空并且 while 语句结束:
void breadth(path const &dir) // starting dir.
{
vector<path> level{ dir }; // currently processed level
while (not level.empty()) // process all its dirs.
{
vector<path> next; // dirs of the next level
for (auto const &dir: level) // visit all dirs at this level
{
cout << "At " << dir << '\n';
// at each dir: visit all entries
for (auto const &entry: directory_iterator{ dir })
{
if (entry.is_directory()) // store all dirs at the current
next.push_back(entry); // level
else // or process its non-dir entry
cout << " entry: " << entry << '\n';
}
}
level = next; // continue at the next level,
} // which eventually won't exist
}
#
4.3.5:文件系统元素的类型(file_type)和权限(perms):file_status
文件系统条目(由 path 对象表示)具有多个属性:权限(例如,所有者可以修改条目,其他人只能读取条目)和类型(如普通文件、目录和软文件)。链接)。
文件系统条目的类型和权限可通过类 file_status 的对象获得。类 file_status 是一个支持复制和移动构造函数以及赋值运算符的值类。
构造函数
explicit file_status(file_type type = file_type::none,
perms permissions = perms::unknown)
为具有特定权限集的特定类型的文件系统条目创建文件状态。它也充当默认构造函数。
构造函数的第一个参数是一个枚举,指定由 path 对象表示的文件系统条目的类型:
- not_found = -1 表示未找到其请求状态的文件系统条目(这不被视为错误);
- none 表示尚未评估文件状态,或者评估条目状态时发生错误;
- 常规:该条目是常规文件;
- 目录:条目是一个目录;
- symlink:条目是符号链接;
- block:该条目是一个块设备;
- 字符:该条目是字符设备;
- fifo:条目是命名管道;
- socket:该条目是一个socket文件;
- 未知:该条目是未知的文件类型
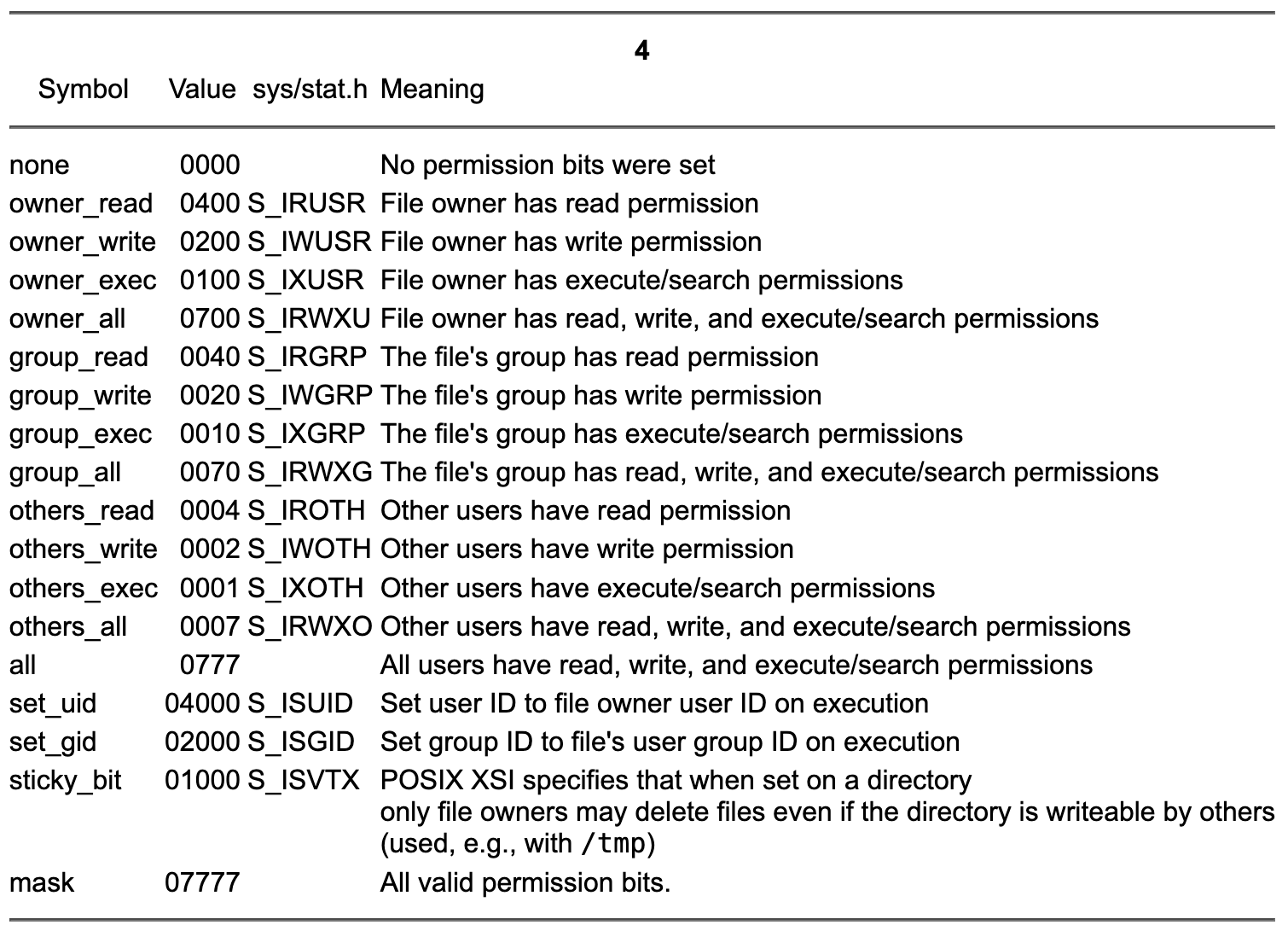
构造函数的第二个参数定义枚举类 perms ,指定文件系统条目的访问权限。选择枚举的符号是为了使它们的含义比 <sys/stat.h> 头文件中定义的常量更具描述性,但除此之外它们具有相同的值。所有按位运算符都可以由枚举类 perms 的值使用。以下是枚举类 perms 定义的符号的概述:
类 file_status 提供以下成员:
-
perms 权限() const 和 void 权限(perms newPerms [, perm_options opts] [, error_code &ec]):
前一个成员返回
file_status对象表示的文件系统条目的权限,后者可用于修改这些权限。枚举类perm_options具有以下值:- 替换:当前选项被newPerms替换;
- add:将newPerms添加到当前权限中;
- 删除:newPerms从当前权限中删除;
- nofollow:当路径引用符号链接时,更新符号链接的权限,而不是更新链接引用的文件系统条目的权限。
-
file_type type() const 和 void type(file_type type):
前一个成员返回
file_status对象表示的文件系统条目的类型,后者可用于设置类型。
#
4.3.5.1:获取文件系统条目的状态
文件系统函数 status 和 symlink_status 检索或更改文件系统条目的状态。这些函数可以使用 final (optional) error_code 参数调用,如果它们无法执行其任务,则为该参数分配适当的错误代码。如果省略参数,则成员在无法执行其任务时将抛出异常:
-
file_status状态(path const &dest [, error_code &ec]):
返回
dest的类型和属性。如果dest是符号链接,则返回链接目标的状态; -
file_status symlink_status(path const &dest [, error_code &ec]):
当调用
symlink_status(dest)时,返回dest本身的状态。因此,如果dest引用符号链接,则 symlink_status 不会返回dest引用的条目的状态,而是返回dest本身的状态:符号链接(file_status的type()成员返回file_type::symlink); -
bool status_known(file_status const &status):
如果
status引用确定的status,则返回 true(status本身可能表明status引用的实体不存在)。接收 false 的一种方法是向其传递默认状态对象:status_known(file_status{});
一旦获得 file_status 对象,就可以使用这些函数(在文件系统命名空间中定义,其中 WHATEVER )来询问其所代表的 status 条目的文件类型要求的规格):
bool is_WHATEVER(file_status status)
bool is_WHATEVER(path const path &entry [, error_code &ec])
如果 status 或 status 与请求的类型匹配,这些函数将返回 true。以下是可用的功能:
- is_block_file:该路径指的是块设备;
- is_character_file:路径指的是字符设备;
- is_directory:路径指的是目录;
- is_empty:路径指的是空文件或目录;
- is_fifo:路径引用命名管道;
- is_other:路径不引用目录、常规文件或符号链接;
- is_regular_file:路径指的是常规文件;
- is_socket:路径引用一个命名套接字;
- is_symlink:路径指的是符号链接;
或者, file_status::type() 成员可以用在例如开关中,以选择与其 file_type 返回值匹配的条目(请参阅上一节 ([4.3.5](/cpp/zh/docs/Name-Spaces/#435-types-file\_type-and-permissions-perms-of-file-system-elements-file\_status)) 了解 file_type
这是一个小程序,展示了如何获取和显示文件状态(有关地图,请参阅第 12.4.7 节):
namespace
{
std::unordered_map<file_type, char const *> statusMap =
{
{ file_type::not_found, "an unknown file" },
{ file_type::none, "not yet or erroneously evaluated "
"file type" },
{ file_type::regular, "a regular file" },
{ file_type::directory, "a directory" },
{ file_type::symlink, "a symbolic link" },
{ file_type::block, "a block device" },
{ file_type::character, "a character device" },
{ file_type::fifo, "a named pipe" },
{ file_type::socket, "a socket file" },
{ file_type::unknown, "an unknown file type" }
};
}
int main()
{
cout << oct;
string line;
while (true)
{
cout << "enter the name of a file system entry: ";
if (not getline(cin, line) or line.empty())
break;
path entry{ line };
error_code ec;
file_status stat = status(entry, ec);
if (not status_known(stat))
{
cout << "status of " << entry << " is unknown. "
"Ec = " << ec << '\n';
continue;
}
cout << "status of " << entry << ": type = " <<
statusMap[stat.type()] <<
", permissions: " <<
static_cast<size_t>(stat.permissions()) << '\n';
}
}
#
4.3.6:文件系统空间信息:space_info
每个现有路径都存在于文件系统中。文件系统的大小通常很大,但它们的大小是有限制的。
文件系统的大小、当前使用的字节数和剩余字节数由函数 space(path const &entry [, error_code &ec]) 提供,返回包含 entry 在 POD 结构 space_info 中。
如果提供了 error_code 参数,则如果没有发生错误,则将其清除;如果发生错误,则将其设置为操作系统的错误代码。如果发生错误并且未提供 error_code 参数,则抛出 filesystem_error 异常,接收 path 作为其第一个参数,并接收操作系统的错误代码作为其 error_code 参数。
返回的 space_info 有三个字段:
uintmax_t capacity; // total size in bytes
uintmax_t free; // number of free bytes on the file system
uintmax_t available; // free bytes for a non-privileged process
如果无法确定某个字段,则将其设置为 -1(即类型 uintmax_t 的最大值)。
该函数可以这样使用:
int main()
{
path tmp{ "/tmp" };
auto pod = space(tmp);
cout << "The filesystem containing /tmp has a capacity of " <<
pod.capacity << " bytes,\n"
"i.e., " << pod.capacity / (1024 * 1024) << " MB.\n"
"# free bytes: " << pod.free << "\n"
"# available: " << pod.available << "\n"
"free + available: " << pod.free + pod.available << '\n';
}
#
4.3.7:文件系统异常:filesystem_error
std::filesystem 命名空间提供了它自己的异常类型 filesystem_error (另见第10章)。它的构造函数具有以下签名(括号中的参数是可选的):
filesystem_error(string const &what,
[path const &path1, [path const &path2,]]
error_code ec);
由于 filesystem 设施与标准系统功能密切相关,因此可以使用 errc 错误代码枚举值来获取 error_codes 传递给 filesystem_error ,如以下程序所示:
int main()
try
{
try
{
throw filesystem_error{ "exception encountered", "p1", "p2",
make_error_code(errc::address_in_use) };
}
catch (filesystem_error const &fse)
{
cerr << "what: " << fse.what() << "\n"
"path1: " << fse.path1() << "\n"
"path2: " << fse.path2() << "\n"
"code: " << fse.code() << '\n';
throw;
}
}
catch (exception const &ec)
{
cerr << "\n"
"plain exception's what: " << ec.what() << "\n\n";
}
@media (prefers-color-scheme: dark) { body { color: #fff !important; background-color: #272727 !important; } } body { overflow-y: hidden; }